上一节,讲解了HDFS的原理,以及相关的hadoop系统安装文档,参考文档可以轻松的搭建好,Hadoop伪分布式集群环境,这一节主要讲解一下如何操作HDFS,及HDFS文件的存储方式。本章对HDFS的常见操作方法做了简单介绍,...
”hadoop 大数据 hdfs shell“ 的搜索结果


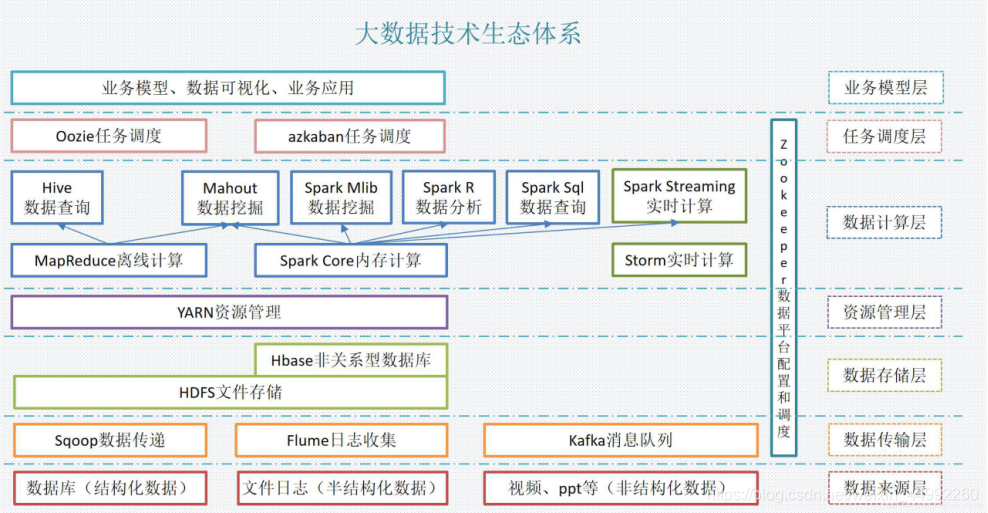
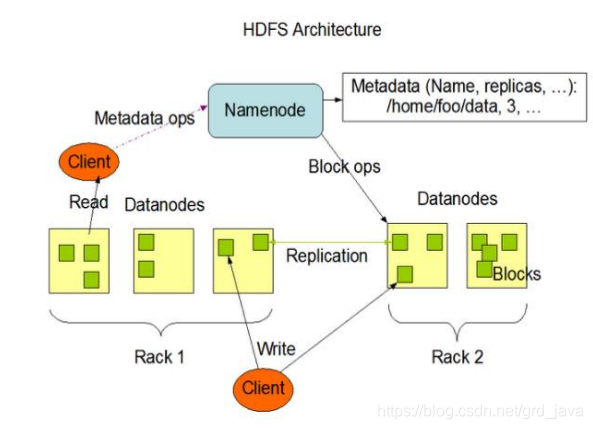
扩容能力强,成本低,高效率,可靠性,高容错演变基本概念名称节点(NameNode)数据节点(DataNode)数据块(Block)机架(Rack)元数据(Metadata)特点优点:高容错,流式数据访问,支持超大文件,高数据吞吐量,...
尚硅谷大数据技术Hadoop教程-笔记03【Hadoop-HDFS】

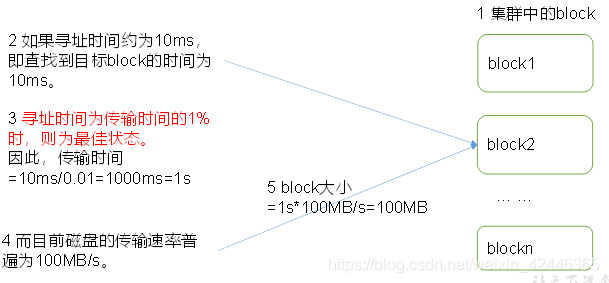
Hadoop默认没有开启机架感知功能,默认情况下每个Block都是随机分配DataNode,需要进行相关的配置,那么在NameNode启动时,会将机器与机架的对应信息保存在内存中,用于在HDFS Client申请写文件时,能够根据预先定义...
HDFS Shell 命令是由一系列类似Linux Shell的命令组成的1、创建文件夹2、列出指定的目录或文件3、新建文件4、上传文件5、将本地文件移动到HDFS6、下载文件7、查看文件8、追写文件9、删除目录或者文件10、显示占用的...
熟悉使用hdfs的shell命令 1、在Downloads目录下创建a.txt,文件内容为:hello 2、在hdfs中创建031701目录 3、将a.txt通过put上传到031701目录 4、将hdfs中的a.txt删除 5、将a.txt通过copyFromLocal上传到031701目录 6...

1.0查看帮助 hadoop fs -help <cmd> 1.1上传 hadoop fs -put <linux上文件> <hdfs上的路径> 1.2查看文件内容 hadoop fs -cat <hdfs上的路径> 1.3查看文件列表 hadoop fs...

大数据HDFS的直接命令行操作,将本地文件上传到HDFS,从HDFS上下载文件,对HDFS文件夹的管理

Hadoop大数据技术原理与应用
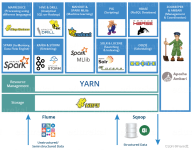
文章目录概述HadoopHDFSHBase实现原理Regin服务器原理HBase安装与使用NoSQL数据库MapReduceHive 概述 IT领域每隔十五年就会迎来一次重大变革: 1980:个人计算机 1995:互联网 ...大数据技术的不同层面
HDFS的Shell操作1、基本语法2、常用命令实操 1、基本语法 bin/hadoop fs 具体命令 或者 bin/hdfs dfs 具体命令 dfs是fs的实现类 2、常用命令实操 (0)启动Hadoop集群 sbin/start-dfs.sh sbin/start-yarn.sh (1)...
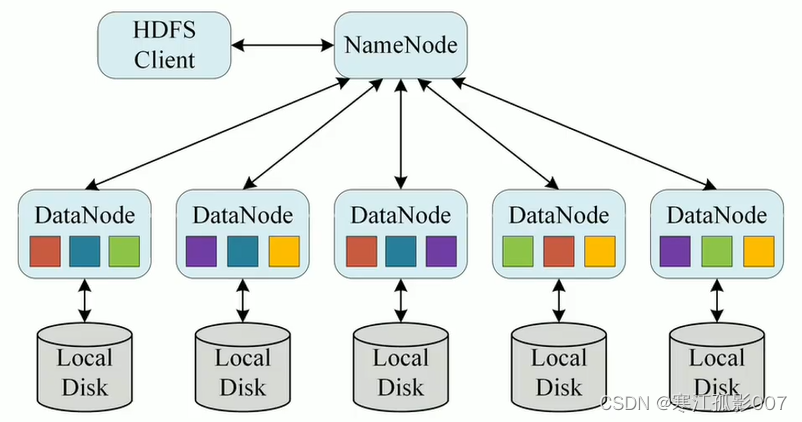
大数据 HDFS的shell操作
标签: 大数据

Hadoop hdfs shell 命令行常用操作
ONBOOT=yesHWADDR=max地址#注意:不能与本地机ip重复#注意:网卡名称不一定是ens33,但是一般都在network-scripts文件下,可以通过tab 或者ls查看文件夹来推测配置完静态网络需重启网络方法一:方法二:ifup ens33。
【代码】Hadoop 3.1.1 HDFS 集群部署。
了解HDFS原理,能熟练地对HDFS中的文件进行管理 能独立完成pig的安装并且利用pig做简单的数据分析工作 能独立完成Hbase的安装和配置 了解Hbase的原理并能进行简单的shell操作 能独立完成Hive的安装和配置 了解Hive的...

推荐文章
- http作业
- KVstore :键值映射存储服务器
- java-php-python-ssm社区志愿者服务管理系统计算机毕业设计_社区 志愿服务系统源码 php-程序员宅基地
- java/php/node.js/python病人跟踪治疗信息管理系统【2024年毕设】-程序员宅基地
- 空间数据引擎oracle_空间数据库引擎及其解决方案分析-程序员宅基地
- java发布rest服务器,使用Java restlet发布到服务器-程序员宅基地
- 使用flex-wrap实现弹性盒自动换行-程序员宅基地
- 改变Android Studio的背景background_as怎么设置背景-程序员宅基地
- 桩筏有限元中的弹性板计算_专栏 l 增材制造点阵结构在压力容器优化设计中的应用...-程序员宅基地
- Firefox安装广告屏蔽插件(uBlock Origin)_ublock origin插件-程序员宅基地